What this package contains¶
Karta Context Engine is an effort to provide high fidelity, well documented and diverse test cases for AI agents from multiple domains. Building reliable agents is hard work. This is an attempt to take the load off developers looking for stable test cases and tools, so that they can focus on fine tuning their agents.
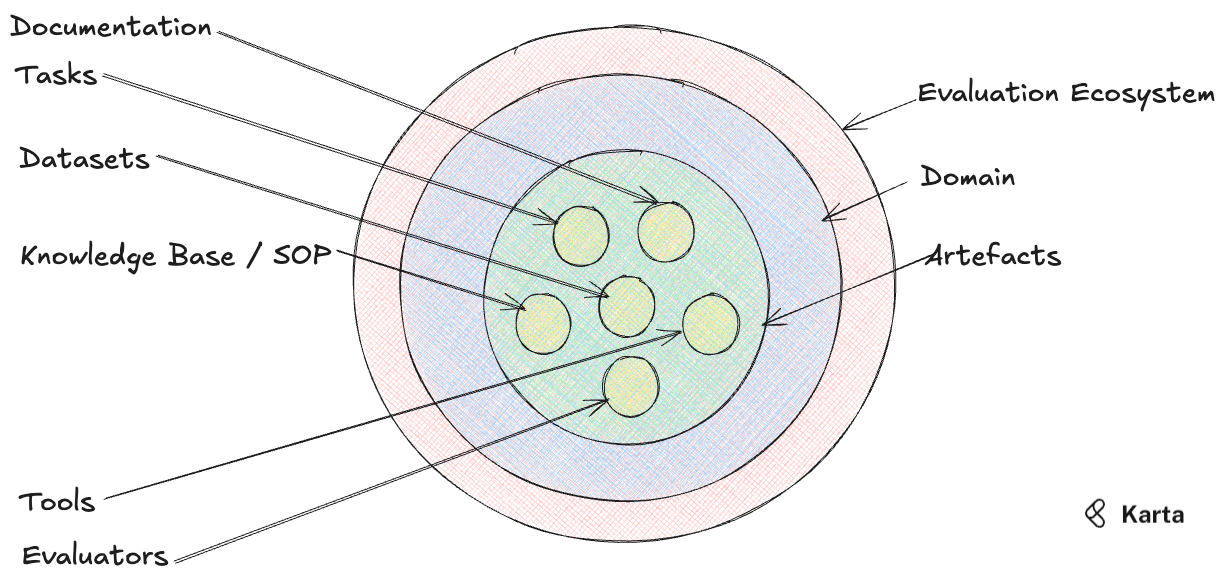
The evaluation ecosystem is what this package provides developers access to. A readymade set of capabilities which allows users to focus on the agent rather on dealing with peripheral issues such as setting up tools and sample databases.
Evaluation data sets are split into multiple domains and each domain comes equipped with a set of artefacts that are self-contained (needing no external data or other user inputs).
A domain refers to a broad industry use case such as e-commerce, fintech .etc. Vocabulary, customer requirements, regulations and other subtleties are expected to vary across domains.
Each domain is equipped with a set of artefacts that developers can integrate directly into their code. Currently we provide 6 artefacts per domain:
Datasets: A simulated database containing artificial data relevant to the domain. Each database comes with multiple “tables”.
Tools: A tool factory that creates and vends the tools (along with relevant documentation) required for agents.
Knowledge Base/ SOP: Ingestable documents containing detailed knowledge and operating procedures specific to a domain.
Tasks: Handpicked tasks along with expected behavior patterns and classifications into different difficulty levels.
Evaluators: A unified evaluation interface that allows agent-user interaction trajectories to be evaluated in a few lines of code.
Documentation: Detailed documentation for each dataset, tool and task.
Data Origins¶
All data in Karta Context Engine is entirely synthetic, generated using structured methodologies informed by domain experts. It is designed to capture the complexity of real-world scenarios without relying on proprietary or sensitive information, ensuring both realism and ethical integrity. By leveraging expert-driven knowledge, the dataset enables rigorous, reproducible evaluations while maintaining adaptability for diverse testing needs. This synthetic approach ensures that AI agents are assessed against well-defined benchmarks, promoting fairness, transparency, and robustness in evaluation.
Continuous Updates¶
The Karta team is committed to continuously expanding and refining the dataset. As new AI agent training methodologies evolve, the team will share the same synthetic datasets used internally to train and evaluate our own models. This ensures that Karta Context Engine remains relevant, up-to-date, and aligned with the latest advancements in AI testing and benchmarking. By regularly incorporating new datasets, the package empowers researchers and developers with cutting-edge evaluation tools, fostering a collaborative and evolving ecosystem for AI agent assessment.
What Do I Get?¶
The Karta Context Engine is built to support different stakeholders in AI evaluation—each with their own priorities and challenges. Whether you’re an engineer , a product manager , or an operations manager , here’s what you can expect to gain from integrating the context engine into your workflow.
For Engineers¶
Easily Importable Datasets : No need to waste time curating test data. Our structured, domain-specific datasets are ready to use, helping you validate AI performance immediately.
Automated Testing Workflows : Reduce manual effort with seamless integration into existing CI/CD pipelines and evaluation frameworks.
Fine-Grained Task Control : Test specific AI capabilities with tailored, well-structured scenarios that closely mimic real-world interactions.
Multi-Metric Evaluation : Run multiple evaluation metrics to compare different AI models and iterate quickly.
For Product Managers¶
Realistic Benchmarking : Ensure AI agents are tested against real-world conditions, reducing unpredictable behavior in production.
Scenario-Driven Validation : Assess AI performance across carefully designed tasks that reflect actual user interactions in your domain.
Domain Expansion : Start with e-commerce and scale into other domains as the library expands.
Clear Insights for Decision Making : Get meaningful metrics that help determine whether an AI model is ready for deployment or requires further improvement.
For Operations Managers¶
Reduced Downtime and Failures : Ensure AI agents are thoroughly tested before they go live, preventing costly failures in customer interactions.
Safe AI Implementation : By using representative task simulations, avoid AI errors that could lead to customer dissatisfaction or operational inefficiencies.
Proactive Issue Detection : Catch AI weaknesses early by stress-testing with edge cases and diverse datasets.
Scalable Testing for Growing AI Needs : As AI-powered operations scale, the Karta Scenario Library provides a structured framework to continuously test and improve AI performance.