Welcome to the Karta Context Engine¶
The journey to building robust AI agents can be challenging. At Karta, we found that existing datasets and evaluation tools for iterating quickly on agent architectures were non-existent. Capturing the subtleties and variety during testing is essential in creating a viable AI experience for customers. Off-the-shelf benchmarks rarely captured the complexities our agents faced in production, leaving critical gaps in their assessment.
Determined to bridge this gap, we set out to create gold standard tasks coupled with deeply representative contexts for Agent evaluation — meticulously designed datasets, well-defined tasks, and comprehensive toolsets tailored to real-world domains. We started with e-commerce, an industry where we have deep expertise, ensuring our evaluations reflect the nuanced interactions that AI systems encounter in practical deployments.
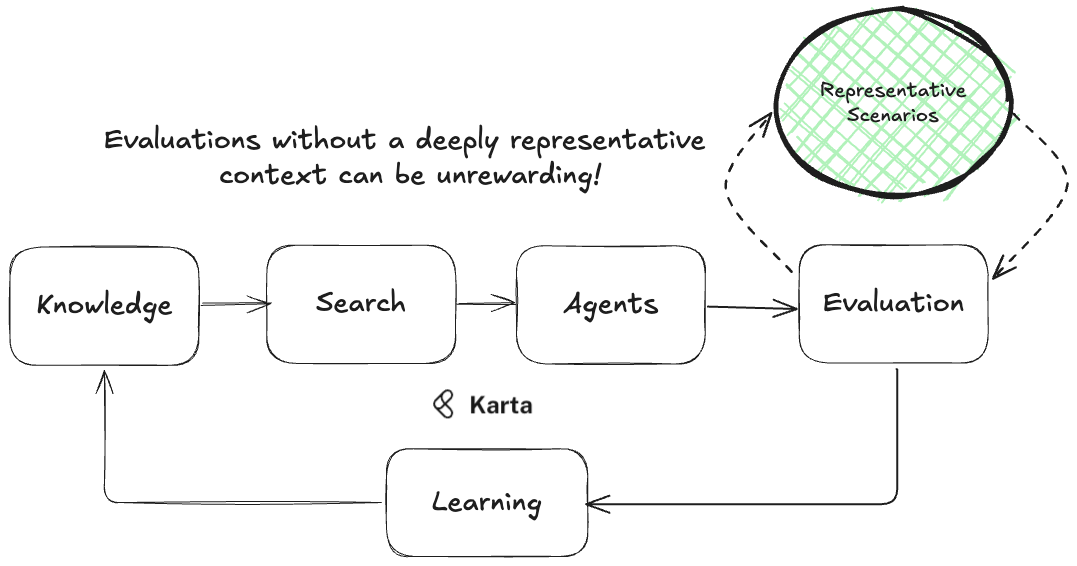
The result is the Karta Context Engine — a comprehensive suite of structured datasets, domain-specific tasks, and knowledge documents crafted to set a new benchmark for AI testing. Designed for seamless integration into existing codebases, it empowers teams to automate testing workflows, run sophisticated simulations, and rigorously validate agent performance. With the Karta Context Engine, AI teams can confidently measure, iterate, and improve, knowing they are testing against some of the most complex and subtle real-world scenarios available.
Our vision is a state where agent evaluation is effortless, rigorous, and representative of real-world challenges. Our journey begins with easily importable datasets that provide developers with quick access to high-quality test cases. From there, we will expand the breadth of supported domains, ensuring that AI agents across industries are held to the highest standard.
The culmination of this effort will be a fully integrated interface for running and comparing multiple evaluation metrics, allowing AI teams to benchmark performance with precision and clarity. We believe that representative task simulations are the key to a safe AI experience, helping developers build models that behave predictably in high-stakes environments. By pushing the boundaries of AI evaluation, we aim to set the foundation for a future where AI is trustworthy, adaptable, and aligned with real-world needs.
Understand the Basics¶
Domain Data¶
Domains: